Field note
Jun 2, 2026
Predictive maintenance in manufacturing: the operator guide
Predictive maintenance in manufacturing only works when operators control the handoff from sensor warning to work order, downtime decision, and verified fix.
Predictive maintenance in manufacturing sounds like the rare automation idea everyone should agree on.
A machine starts drifting. The system notices early. Maintenance gets the warning before the line goes down. Production keeps moving. Finance stops learning about equipment problems through missed shipments. Everyone claps politely and pretends the old spreadsheet never existed.
The messy version is less cinematic.
A vibration alert shows up in one tool. The work order lives in another. The supervisor does not know whether the part is on site. Production does not want to stop the line for an inspection. The technician has seen too many false alarms, so the warning becomes background noise. Two weeks later the asset fails, and the postmortem says the model technically flagged it.
That is not a model problem first. It is an operating handoff problem.
Moore IQ starts these projects the same way we approach AI automation for facilities and maintenance teams: decide which decision the system is allowed to influence, which human owns it, and what evidence proves the warning changed the work.
Predictive maintenance is a decision system, not a sensor project
A predictive maintenance project usually gets described in equipment terms: vibration, temperature, pressure, runtime, oil analysis, fault codes, inspection history, and machine learning.
Those inputs matter. They are not the outcome. NIST frames smart manufacturing around connected systems and operational data, which is useful context, but a plant still needs the operating decision attached to the data.
The outcome is a better decision before downtime happens. Should the line keep running? Should maintenance inspect now? Should a work order be created? Should parts be pulled? Should production schedule a planned stop? Should a supervisor override the alert because the asset is already under observation?
If the project cannot answer those questions, it will become another monitoring feed.
A useful manufacturing workflow turns a signal into a controlled sequence:
- Detect the asset, failure mode, confidence level, and operating context.
- Check whether the asset is already under a work order or planned outage.
- Create or update the work order with the evidence attached.
- Assign an owner and response window.
- Check parts, safety requirements, and production constraints.
- Escalate if the decision stalls.
- Record what happened so the next prediction gets smarter.
That sequence is the difference between predictive maintenance and expensive noise.
It also explains why the CMMS handoff problem matters so much. The sensor layer can be right and the plant can still lose if the warning does not land inside the system people already use to plan work.
Pick one constrained asset first
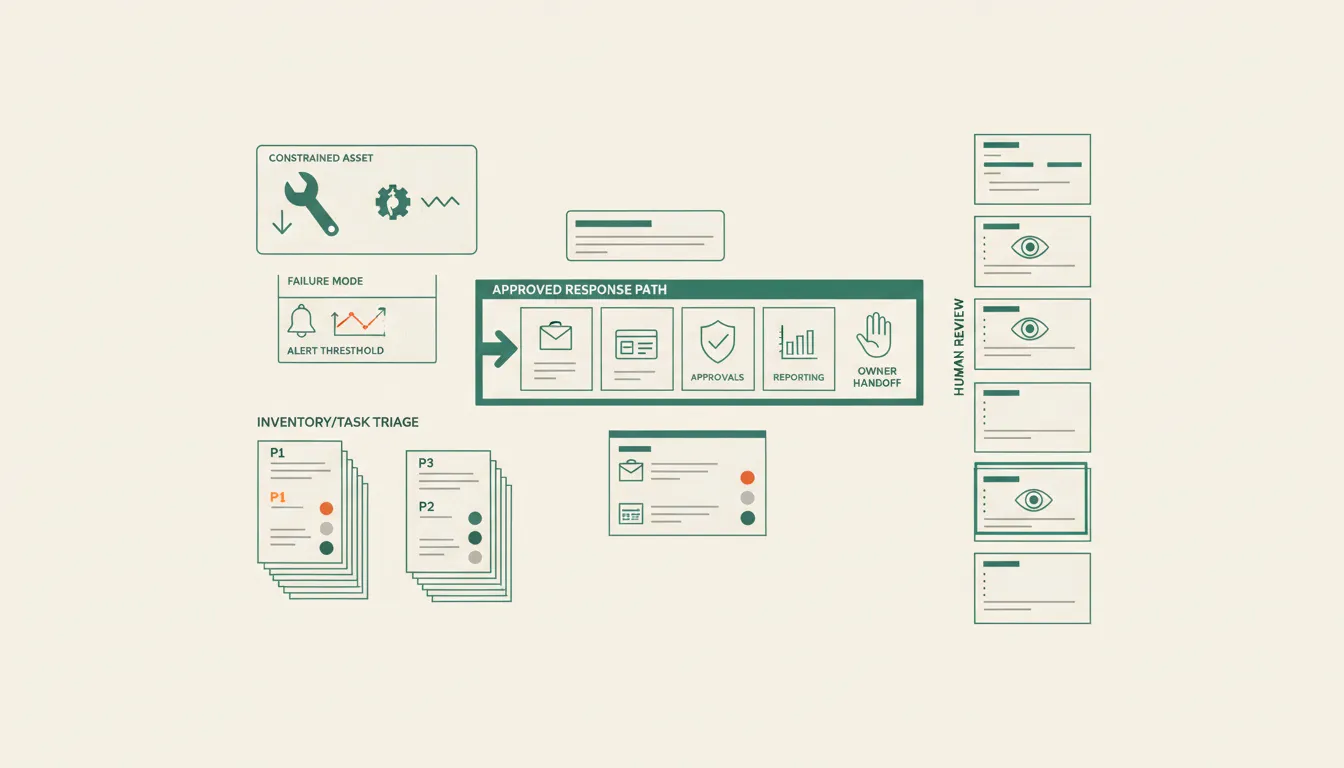
The first predictive maintenance build should not cover the whole plant.
Start with one constrained asset where downtime changes money, customer promises, or safety planning. A constrained asset is not just expensive equipment. It is equipment whose failure forces visible tradeoffs: a press that bottlenecks production, a compressor that feeds multiple lines, a conveyor that backs up shipping, a pump that creates sanitation or safety risk, or a motor whose emergency replacement disrupts the week.
Then narrow again to one failure mode.
Do not ask AI to understand every version of machine health. Ask it to support one known decision. For example:
- A vibration pattern that has preceded bearing replacement.
- Temperature drift that has led to unplanned stoppage.
- Repeated fault codes that technicians already recognize.
- Inspection findings that often become emergency work.
- Runtime thresholds that require planned maintenance before a rush order window.
This is where many teams overbuild. They buy a platform, connect assets, and then wait for the system to reveal the magic. The operator version is smaller and less glamorous. It says, "When this asset shows this signal, who decides what happens before the next shift?"
That question keeps the project honest.
It also protects the team from a common trap: treating the prediction as the hard part while ignoring the response path. The response path is where the plant either saves the day or creates a new admin chore.
Connect the warning to the work order
Predictive maintenance only changes operations when the warning reaches the work queue.
In most manufacturing environments, that means the CMMS, an ERP maintenance module, a planner board, a supervisor task queue, or a hybrid process that nobody is especially proud of but everyone uses. The exact system matters less than the ownership rule.
A warning should not say, "Asset 14 looks risky."
It should say:
- Asset 14 shows elevated bearing risk based on the last three readings.
- No open work order exists for this failure mode.
- The line is scheduled for a lower-volume window tomorrow afternoon.
- The replacement part is on hand, or it is not.
- Maintenance supervisor review is due by 2 p.m.
- If no action is taken, escalate to production and maintenance leadership.
That is a workflow. It gives the plant something to do.
The same pattern appears in work orders from email: extraction is not enough. The system has to route the request, attach context, and preserve human review when the risk is ambiguous.
Predictive maintenance should do the same. It should create fewer vague warnings and more decision-ready work.
Standards bodies frame this as part of a broader management system, not a standalone gadget. ISO 55001, the asset management standard, focuses on coordinated activity to realize value from assets. The standard itself is not a software requirement, but the operating lesson is useful: asset decisions need ownership, context, and evidence, not just data. ISO describes the asset management standard at iso.org.
Keep safety and production constraints visible
A maintenance prediction is not automatically permission to touch the machine.
Plants have lockout rules, production commitments, sanitation windows, labor availability, and customer deadlines. If the predictive layer ignores those constraints, it will either be ignored or become dangerous.
The workflow should show safety and production context before recommending action. At minimum:
- Does inspection require lockout or a planned stop?
- Is the asset running a rush order today?
- Is there an approved maintenance window?
- Are the parts and technician skills available?
- Is the same warning already covered by an open work order?
- Who can approve a line interruption?
OSHA's control of hazardous energy guidance is a useful reminder that maintenance work is not just a scheduling problem. Equipment inspection and repair can create serious risk when energy control is unclear. The OSHA page on control of hazardous energy is worth keeping close to any workflow that moves from warning to intervention.
For a buyer, this is the governance question. The vendor demo may show an early warning. Your plant still needs the approval path.
That is why Moore IQ favors review-mode automation first. The system can detect, summarize, draft the work order, check parts, and notify the owner. It should not silently interrupt production or dispatch maintenance into a risky job without the plant's rules attached.
Build the exception queue before the dashboard

Most predictive maintenance dashboards are built for looking impressive in a meeting.
Operators need a queue.
The exception queue should show the cases that need a decision today:
- Critical asset warning with no work order.
- Work order created but no owner assigned.
- Part unavailable for a high-risk asset.
- Inspection completed but result not recorded.
- Repeated alert ignored more than once.
- Planned outage exists but maintenance task is not attached.
- Prediction disagrees with technician judgment and needs review.
Each row should include asset, failure mode, confidence, evidence, owner, due time, work order status, parts status, safety note, and production constraint. If the row does not drive a decision, it does not belong in the first version.
This is also where n8n consulting can be useful. n8n is not the predictive model. It can be the routing layer that listens for sensor events, checks the CMMS, enriches the record, posts the exception, and keeps an audit trail while the plant decides what to automate next.
The queue should be boring by design. Boring means technicians trust it, supervisors can act on it, and leadership can see whether warnings are becoming completed work.
What to measure after the first month
Do not judge the first month by the number of alerts.
Judge it by whether the plant made better decisions:
- Warnings that became reviewed work orders.
- Warnings ignored or dismissed with a reason.
- False positives by asset and failure mode.
- Missed failures that were not predicted.
- Work orders completed before unplanned downtime.
- Parts shortages found before the maintenance window.
- Supervisor approvals completed on time.
- Production interruptions avoided or moved into planned windows.
Those numbers tell you whether predictive maintenance is becoming an operating system or just another chart.
They also tell you when to expand. Add the next asset only after the first workflow proves that warnings become decisions. If the team is still debating ownership, do not add sensors. Fix the handoff.
The same idea shows up in the vendor dispatch and SLA tracking workflow. Better operations come from making stalled decisions visible, not from producing more activity data.
When not to hire us for predictive maintenance
Do not hire us, or anyone else, to build predictive maintenance if the plant cannot close basic work orders consistently.
If technicians do not record outcomes, supervisors do not own review windows, parts status is unknown, or production refuses to define approval rules, AI will not fix the maintenance operation. It will make the confusion faster and harder to debug.
It may also be too early if the asset is low consequence. If failure is cheap, visible, and easy to fix, a predictive layer may cost more attention than it saves. Start where downtime is painful enough to justify the operating change.
The right first version is narrow: one constrained asset, one known failure mode, one review queue, one response path, and one scorecard.
That is how predictive maintenance in manufacturing becomes useful. Not by predicting everything. By helping the plant act earlier on the few warnings that actually change the week.
If you know the asset that keeps ruining the schedule, start there. If you do not, run the AI Operations X-Ray and map the maintenance handoff before adding another dashboard.
Related field notes
FAQ
Frequently asked questions
- 01What is predictive maintenance in manufacturing?
- Predictive maintenance in manufacturing uses equipment data, operating context, and maintenance history to flag likely failures before they interrupt production. The useful version connects that warning to a work order, owner, parts check, and downtime decision.
- 02What should manufacturers automate first?
- Start with one repeatable failure mode on a constrained asset: bearing temperature drift, vibration on a critical motor, recurring compressor faults, or inspection findings that already trigger emergency work. Prove the handoff before adding more assets.
- 03Does predictive maintenance replace a CMMS?
- No. The CMMS should usually remain the maintenance system of record. Predictive maintenance works as a signal and routing layer that creates better work orders, escalates exceptions, and keeps supervisors from missing early warnings.
- 04How do you avoid false alarms?
- Treat every prediction as a reviewed operating signal until the plant has enough evidence. Track false positives, missed failures, ignored alerts, completed inspections, and production impact. A model that nobody trusts will become noise.
- 05When is predictive maintenance not worth it yet?
- It is usually too early when equipment history is missing, technicians cannot close work orders consistently, parts availability is unknown, or leadership wants AI to compensate for unclear maintenance ownership. Fix the operating basics first.
Related reading
- Why Power Automate Desktop hurts facilities ops at scale
Power Automate Desktop looks like a free win for facilities maintenance teams. Single-machine it works fine. At ten sites and real ticket volume it cracks in predictable ways.
- Before you replace your CMMS, automate these 5 handoffs
A CMMS replacement is expensive, slow, and often unnecessary. If the pain lives in intake, dispatch, inspections, reporting, or vendor follow-up, automation around the system usually pays back first.
- Vendor dispatch and SLA tracking for facilities teams
Vendor dispatch breaks when status lives in email threads and SLA risk is noticed too late. The fix is an automation layer that sends, watches, escalates, and summarizes vendor work without replacing the CMMS.